
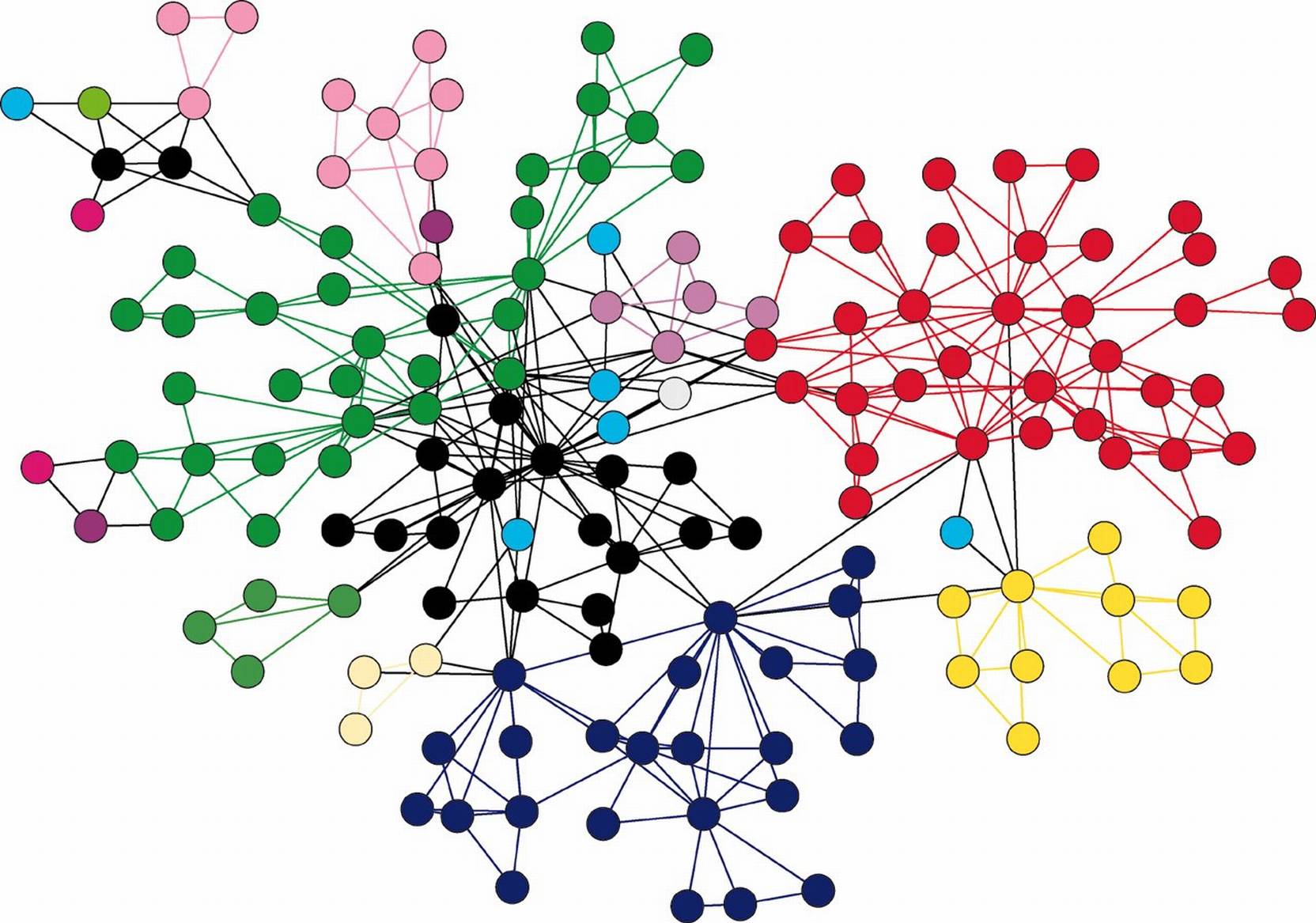
What is a “Graph”?
In mathematics, and more specifically in graph theory, a graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense “related”. - Wikipedia
Without going into mathematical complexities, a graph basically is a diagram with dots (vertices) and lines (edges) joining them. When we talk about graph data structure, we are talking about a set of entities or nodes which are related to each other in some way, and the relationships are represented with directional lines or arrows. Like, in a school model, a (teacher) -[teaches]-> a (student), a (student) -[studies]-> a (subject) etc.
(Ms. Das) -[teaches]-> (Nandini) (Neha)
| ^ | |
[is neighbour of] [studies] [is friend of]
V | V V
(Mr. Iyer) -[loves]-> (Geography) <-[hates]- (Ramesh)
In the above graph, we have
- 6 (nodes) of 2 types, person & subject
- 7 [relationships]
Characteristics of a Graph Database
A graph database is very different from other type of databases (e.g. relational, document, key-value) such that, it [1] actually stores the data in a graph structure, and [2] treats relationships between different pieces of data with the same importance of data itself. So data models, internal storage and data retrieval, all revolves around data and relationships. Some main features of standard graph databases are
- Stores data in graph structure - has nodes & relationships
- Data stored in nodes, represent real-world entities (like objects in OOP), and have properties
- Relations are first class citizen of the system
- Relations are not conceptual, they are as real as the data itself (unlike relational database, where data are stored in rows, but relationships are formed based on foreign-key primary-key equality)
- Relationships can also have properties
- Relationships are named & directed (between a pair of nodes)
- Data models are intuitive - they are basically how developers explain them on white-board! They are easier on brain, to read & write
- Data retrieval is very fast for highly related data, even with huge number of nodes
- Flexible data structures - nodes do not have fixed schema (just like document databases), and any node can have relationship with any other node
- Is a no-sql database, has own query language
- Related data are fetched with patterns (unlike joins in relational databases)
So, in real life systems, when we have data with lot of relationships among them, and we are interested around how data pieces are related to each other, want to search data with arbitrary multi-level relationships, graph databases provides us with very powerful set of tools. Conceptually, a graph is how real life things are actually connected with many level of arbitrary relationship other among things, where relationships can also change over time.
Some very common use cases of graph databases are - social networks, recommendation systems, master data management, network operations (well, graphs are basically networks), any graph based searches etc.
The neo4j database
Neo4j is the oldest & most widely used graph database* in market that has all the above properties. It supports ACID transactions. It also provides great real-like visualizations to see and interact with data, comes with many other great features, and offers a rich set of REST APIs that enable interacting with data. With this available, virtually all programming languages & platforms can use neo4j. It is open source on GitHub.
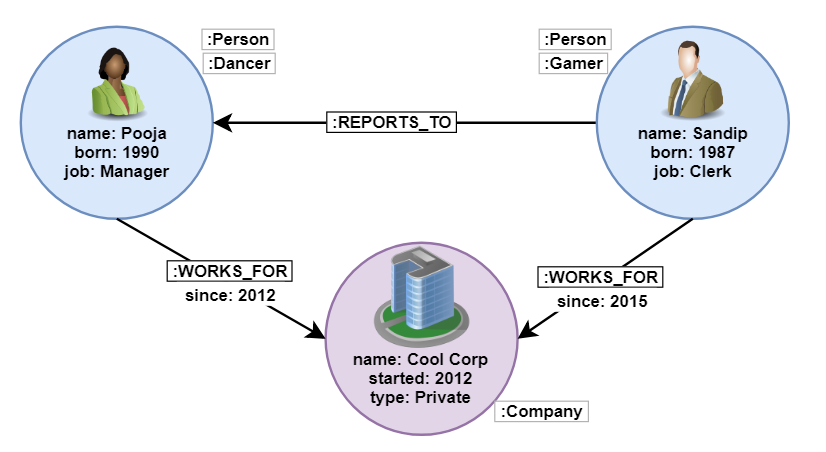
Neo4j data model has 4 main constructs - nodes, relationships, properties & labels.
Neo4j follows the Property Graph Model. That states, relationships are always between a pair of nodes and are directed. Properties are also stored with nodes & relationships. It’s also called Labeled Property Graph as the nodes can have one or more labels. Labels are like tags, which generally talk about the “type of node”. With this, we can identify and group nodes. Labels can be thought to be somewhat relatable to tables in relational databases (because that is how we group similar data there), but actually they are not. Also, nodes can have multiple labels, like a node can be person, teacher & photographer.
Editions - Neo4j offers different editions for different needs, from free community edition to data heavy & scalable enterprise edition. Choose the one that fits your needs.
Drivers - Neo4j has drivers for most of the popular platforms like Java, .NET, JavaScript, Python, Go etc.
Installation
Neo4j runs on all major platforms viz. Windows, Linux & macOS etc. For all the platforms, it (we’ll see the community edition here) supports running as a command-line application as well as an installed service. For Windows systems, it also offers a simple GUI module. Let’s quickly install it as service on a Windows system, with the zip package. Alternatively, you can also run the exe from the same page below.
- See the options here or directly download the zip for Windows here
- Before installation, install JRE 8 from here. Remember, you may have to set the
JAVA_HOMEenvironment variable in Windows, to the bin of installed JRE. - Extract the contents of the zip from “neo4j-{version}-{platform}.zip{platform}-{version}” in a directory with access, e.g.
C:\neo4j - Open command-prompt in the “bin” directory with admin access
- Run
neo4j install-serviceto install neo4j as service - Run
neo4j startto start the service. To stop, runneo4j stop
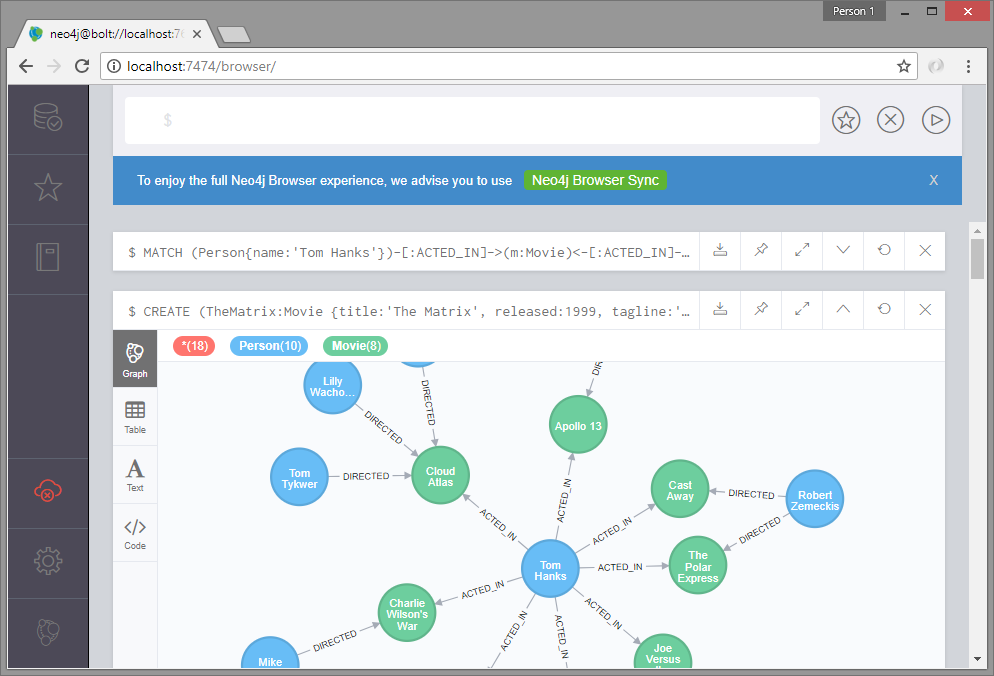
Once the service is started, visit the web interface at http://localhost:7474/browser/, login with the default credentials username: neo4j, password: neo4j.
You can directly run queries here on top section, and see the result below. It also provides access to settings, documentation and other useful stuffs on the left menu.
To make any settings change, update the neo4j.conf file inside conf directory. Find the line with related settings, uncomment and make necessary changes. You may need to restart the neo4j server for the changes to take effect.
dbms.connector.http.listen_address=:7900 #change default port from 7474 to 7900
dbms.connectors.default_listen_address=0.0.0.0 #make it accessible over network
Graph and other databases
There are different types of database and they all have their rightful places. There is no one-size-fits-all solutions and it needs thoughtful consideration to select a specific database for an application. It depends on the specific use-cases, common query needs, infrastructure, cost, team-expertise, type of application and many other factors.
Here we’ll look at some common types of databases and when it “might” be more useful than others. But understand every project/application is different and only a person with enough knowledge of the application should be able to select a database. Also, in most of the complex application needs, it’s not just one database, but a combination of different data storage strategies that gives a good-enough solution.
Relational database
Relational databases like MySQL, Oracle, SQL Server etc. works really well, when storage & data retrieval needs align with their capabilities. They are great at maintaining fixed structure data and running table-level queries with not-so-many relationships between big set of tables. Beyond that, the queries with lot of joins tends to degrade in performance. Prefer it when
- Data is well defined & fixed structured, with limited level of pre-defined relationships (decided at design time)
- Lot of column based aggregations are used (e.g. ranking queries, or average, standard deviation etc.), as column-wise retrieval is pretty fast
Document database
Document databases like MongoDB, Couchbase stores data in JSON-like format, where all the data related to a central entity is stored as a single document. They are generally schema-less and provides great read speed as all the required data is at one place. Generally, document databases also support foreign keys & joins, but does not perform that great when we want to fetch related data from multiple documents. Because of its nature, it’s also easier to distribute & physically shard the database, as related data always stays together. Prefer it when
- We want to store and retrieve big chunk of data about a specific entity (e.g. all data related to one user in an e-commerce system is saved as one document. So, for example, the product details are stored with each user’s, each order. Normalization is not a priority) with high-speed reads
- When data model changes regularly, as document databases are generally schema-less
Graph database
Both the above type of database performs very poorly when data has multi-level arbitrary relationships. Graph data performs really well when we want to relate among arbitrary (not very closely related or obvious) set of data with semantically rich & diverse set of relationships. It can traverse the graph structure and find relationships and data spread across many nodes. With more hops (traversing from one node to another), the speed decreases, but not much.
It works really well when we have queries like (e.g. around an e-commerce system)
- “Which all customers have bought Camlin ball pen from that supplier?”
- “Which all customers bough the same items as Madhu?”
- “Who shopped last week and bough most items common as Sumit?”
- “Is there any relationship between entity X and Y, and if yes, how?”
Other type of databases also provide great value in specific use-cases, like key-value databases (like Redis, Memcached) for caching, text-search databases (like Elasticsearch, Solr) when we want to search text data with arbitrary keywords or phrases etc. This article also provides quick comparative study.
Note: In the next section, we’ll see how to work with graph data in Neo4j with Cypher. We’ll use Cypher query language to fetch & update data, build index and much more.
References
- Introduction to graph database, property graph model
- Graph databases for beginners articles
- Youtube series
- Sample use cases
- Ebooks, including free