

GraphQL
The term GraphQL has been around for quite a while, but still it is not very clear to many developers what it really is! At least it wasn’t for me. Also, many people relate GraphQL and Graph Databases, which are actually not related in any way! Some of the definitions on the internet can also be confusing! So let’s just try simplify the terminology & wrap our head around the basic concepts, and see if it can help us solve some of our real life problems.
What is GraphQL
GraphQL is an API standard. It defines a way of building smart APIs where the client can ask for exactly what data is needed, and the API server returns the same data as requested by the client.
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. - GraphQL home
GraphQL stands for “Graph Query Language”. It’s not a database query language like SQL, it is a way of building standard APIs like REST principles, which allows data queries. It can also be thought of as a smart way of fetching data.
GraphQL was initially designed in Facebook for their back-end services for web & mobile clients. It was made open source in 2015 and now it’s supported by a large community.
Since it’s more of a standard than a specific implementation, it’s possible to use them on almost any platform. There is already support in many languages for GraphQL servers & clients including JavaScript, Java, C#/.NET, Go, Python, Scala etc.
Why & How
GraphQL was initially developed to overcome some of the limitations of the standard REST APIs. We all know REST APIs are great and they power most of the small-large applications today. But, it has its own limitations.
The REST endpoints are generally like this
/users #Get all users
/users/id #Get a specific user
/users/id/email #Get an user's email
/users/id/skills #Get an user's skills
The main problems with this are
- When we ask for user data, we get all the info (name, email, dob, sex, department, accounts etc.) about the user. But we might need just a few pieces of the info (e.g. name & email), rest are redundant for the client. This unnecessary data increases the payload, eats up more memory to process and slows down the network calls.
- If you want multiple pieces of small info e.g. email & skills (maybe you are a recruiter), you have to make multiple calls. Adds performance overhead and complexity.
- As more and more data are made available through the APIs, the developers have to keep adding and maintaining more and more APIs.
GraphQL aims to solve these problems.
GraphQL lets the client define exactly what data it is looking for, and GraphQL servers are capable of parsing the query and serving exactly what is requested. Let’s take an example
//Client asks for
query {
user (id: 1291) {
email,
skills,
knowsHtml
}
}
//Server returns
{
"data": {
"user": {
"email": "cooldeveloper@email.com",
"skills": [ "Golang", "Scala", "REST", "GraphQL" ],
"knowsHtml": true
}
}
}
Note: With GraphQL you can build a smart API with just one endpoint. On the same endpoint, client can request any data that it wants, and the server responds with that exact data in the same requested format.
The name “GraphQL” came from the idea, that it lets you “query” (QL = Query Language) through the nested structure of data, which is like a “graph”. Generally, it also supports mutation or data update.
How does it work
GraphQL works based on 3 main components
- Type / Schema
- Query
- Resolver
Since the client can query the data model, it’s required to have a clear definition of the data model. GraphQL servers define the structure of data through types or schema. Different languages can define the schema in their own way, but on a high level they all basically specify what fields are available and what are their types. Without being specific to a language, let’s see what the type definition looks like in general. For more details, see the documentation here.
type User {
id: ID,
name: String,
email: String,
dob: Date,
skills: [String],
address: Address
}
type Address {
streetLine1: String,
streetLine2: String,
city: String,
state: String,
zip: String,
country: String
}
With the type or schema defined by the server, the client knows what all data it can query for. Now, based on need, client can query for the exact the data it needs.
In the query, the required fields/properties of data are listed. For nested types, the fields of the child types also need to be defined. For the root object, or nested types or arrays, parameters can also be passed to narrow down specific data (e.g. id:1234 to ask for data related to item with id=1234), define format etc.
GitHub provides a nice interface to write interactive GraphQL queries on its live, public data. Check it out here and do try out some queries.
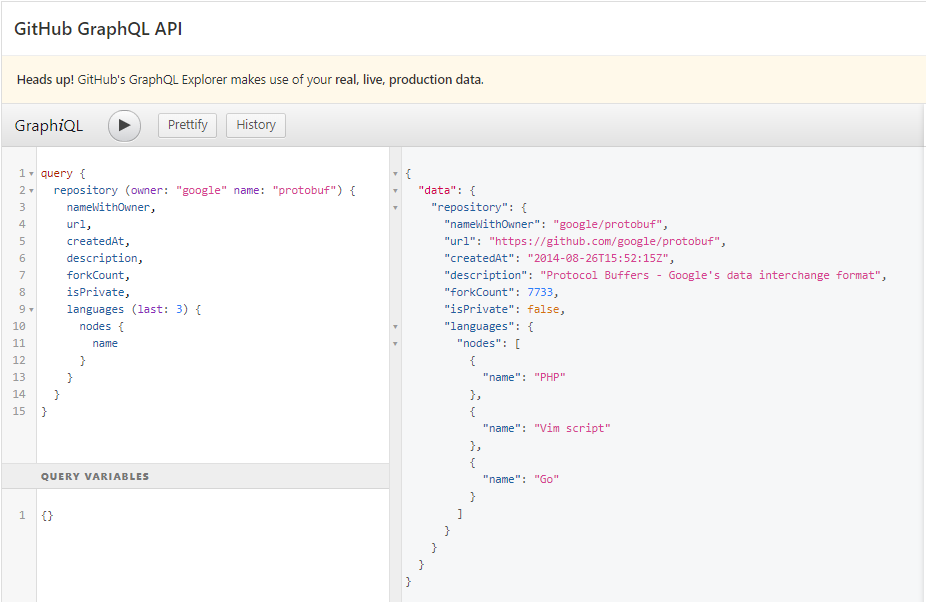
Now, on the API side, the server needs to know how to fulfil the queries. To do this, the GraphQL servers use some specialized GraphQL execution engine that knows how to get data for each fields defined in the schema and combine them into requested form.
So when the server receives the query, it parses and executes the query. If something is found wrong (e.g. a field that is not defined in the schema), it throws a user-friendly message stating what went wrong with the query.
Generally it produces a bunch of smaller queries to fulfil individual fields requested in the query. Then the execution engine tries to run all the queries in most efficient manner, concurrently and combines them back to produce the final result. This result is sent back to the client in the original requested format, generally as JSON.
Note: There is no constraint on the source of data. For example, it’s totally fine to get some audit records from a SQL Server database, user document from MongoDB and transaction details from another API.
The actual implementation of the resolver is technology specific. But again, without going into a specific technology or language, a resolver is a function for each field in the schema, that defines how to fetch the data for that field. Each field resolver function can fetch the data directly from a database, or from the data already fetched for the parent type, or get it from filesystem or another API or any possible source.
A typical code for a type resolver would look something like this
User ResolveUser(int id) {
var user = db.Get<User>(u => u.id == id); //the type
user.AddField(u => u.Id); //standard field resolvers
user.AddField(u => u.Name);
user.AddField(u => u.Email);
user.AddField("totalUsers", (db, u) => db.Users.Count()); //custom resolvers
user.AddField("skills", (db, u) => u.Skills.Select(s => s.Name).ToArray());
return user;
}
Some common questions
- Is GraphQL related to Graph Databases? No. Not at all. GraphQL is an API standard, much like REST. It has nothing to do with any specific database technology. a GraphQL server can be implemented with any backing database given a proper resolver is in place, which can translate GraphQL queries to results.
- Does that mean all REST services will be replaced with GraphQL APIs? No. REST, SOAP, GraphQL and everything else has its pros and cons. For many applications, the current REST APIs are sufficient, and there is no need to change anything. Specific applications that need lot of flexibility and clients are smart enough to query specific data, those can benefit from GraphQL.
- What technology is required to use GraphQL? Since GraphQL is a standard and not an implementation, there is no technology constraint as such. Virtually any tech-stack or programming language can be used. But it’s better to use it with one of the existing GraphQL solutions which are well tested and supported.
References
- The GraphQL homepage
- GitHub repos
- Official docs
- GraphQL specifications
- How to GraphQL - tutorials
- A great intro to GraphQL