
This article talks about Cypher query language for Neo4j graph database. Before going into the details of Cypher, read the introduction to graph database first.
What is a “Cypher”?
Cypher is the neo4j query language. Cypher (pronounced psy-pher) is a query language designed specifically for neo4j graph database, that is being adopted in other graph systems as well. Cypher is used to both manipulate & query data in graph databases. It is generally easier to learn compared to SQL, also easier to read & write. Learn more about Cypher here. Some of the main features of Cypher are
- It is a declarative query language. It specify “what data to fetch” rather than “how to fetch the data”, unlike SQL
- Queries follow the pattern -
MATCH <PATTERN> COMMAND, where COMMAND can be RETURN, CREATE, MERGE, DELETE etc. - The main query logic for any CRUD operation, are in the pattern. A pattern represents what data we are interested in
- It also uses bunch of common SQL-like constructs e.g. WHERE, OREDR BY, MAX, MIN, EXISTS, IN, UNION, STARTS WITH, RANGE, DISTINCT etc.
- It supports many graph-specific constructs (which are not available by default in other database query languages) like - get shortest distance between nodes, find all relationships between a pair of nodes, n-th level relationships etc.
Patterns in Cypher

Pattern contains the data-matching logic, based on which data is either retrieved or manipulated in neo4j database. Patterns are like ASCII-art, i.e. representation of the actual (part of) graph with ASCII characters. The above shows a sample Cypher query, where the (:Book) -[r]- (:Author) part is a pattern, it says a node with Book label is related to a node with label Author.
In Cypher pattern, nodes are shows as () and relationships as -[]->. The arrow head shows the direction of relationship and is optional in some cases. Let’s look at a more complete query below.
MATCH path =
(p:Person) -[r:ACTED_IN]-> (m:Movie)
RETURN p.name, m.title
Here, :Person and :Movie are labels of nodes. The relationship is :ACTED_IN and p, r, m are variables representing the corresponding nodes and relationship.
The Cypher keywords (like MATCH, RETURN) are not case-sensitive, but it’s general convention to write them in upper case. On the other hand, the property, labels & relationships are case-sensitive. Also by convention, property names, variables and functions like count(), exists() are written in lowercase/camel-case.
Path. A whole relationship sequence, including the nodes and relationships, is called a path. The path in above query is just a variable name for the path expressions (p:Person) -[r:ACTED_IN]-> (m:Movie) though.
Note: The colon(:) in node & relationship is optional but important. It can be omitted if node label or relationship type is not specified. If they are required for the pattern, it MUST include the colon. Otherwise the text will be considered as a variable name.
Data creation
Here we’ll see how to create data in neo4j with Cypher query. CREATE is used to create nodes and relationships. MERGE can be used in place of CREATE, to optionally create the data (including nodes & relationship) if it does not exist already, else it’ll just return the existing one.
Properties are created as {key: 'Value'} pairs and the data-type is interpreted by neo4j from the data. Properties can only be of primitive types, that includes - boolean, byte, short, int, long, float, double, char, string and their arrays, like int[], char[] etc. Null is not a allowed value.
For string properties, either quotes (‘value’) or double-quotes (“value”) can be used, both works the same way.
//create 1, 2 nodes. // for comment, end ; is optional
CREATE (n);
CREATE (n),(m)
//create a node with a label & property
CREATE (:Author {name: "Herge"})
//create a node with label, properties and return the created node
CREATE (b:Book{name:"Tintin in Tibet", languages:["English", "Hindi", "French", "Turkish"], isbn:"aa001", year:1960, isPdf:true})
RETURN b
//create two nodes WITH a relationship
CREATE path = (:Book{name:"Chacha Chowdhry 4", languages:["Hindi", "Bengali", "Marathi"], isbn:"aa002", year:1998, isPdf:false}) -[:IS_WRITTEN_BY]-> (:Author{name:"Pran"})
RETURN path
//create a relationship between two existing nodes
MATCH (a:Author {name: "Herge"}), (b:Book {name: "Tintin in Tibet"})
CREATE (b) -[:IS_WRITTEN_BY]-> (a)
//create a node with two labels
Create (tintin:Character:Fictional {name: "Tintin"}) RETURN tintin
//create a relationship between two existing nodes, with a property
MATCH (b:Book), (c:Character)
WHERE b.name = "Tintin in Tibet"
AND c.name = "Tintin"
CREATE path = (b) -[:HAS_CHARACTER {type:"Main"}]-> (c)
RETURN path
//create node if not there already - MERGE
MERGE (c:Character {name: "Sabu"})
RETURN c
Run call db.schema() to see a high level schema or relationship between all nodes & relationships.
Note: When any data is inserted into the database, neo4j creates an internal <id> property which has incremental integer value, starting at 0. It is unique across all nodes and cannot be customized. For querying, the value can be fetched with id(n) function.
Querying data
Here we have some very basic queries to fetch data, based on the data created above. Queries are all about patterns. The result set can be customized with custom column names with AS, can be sorted with OREDR BY [DESC], paginated with SKIP and LIMIT etc.
While creating data, the direction of a relationship is required. For querying data, the direction is optional. If no direction is specified in a query () -[r]- (), relationships in either direction is matched with the pattern.
//get all nodes
MATCH (n) RETURN n;
//get all nodes with <id> less than or equal 100, with custom column names and ordering
MATCH (n)
WHERE id(n) <= 100
RETURN id(n) AS Id, n.name AS Name
ORDER BY id(n)
//get all nodes with Book label, up to 10 items
MATCH (n:Book) RETURN n LIMIT 10
//get all nodes, that HAS isbn property AND is not empty
MATCH (n) WHERE n.isbn <> '' RETURN n
//get all nodes that does NOT have isbn property
MATCH (n) WHERE NOT exists(n.isbn) RETURN n
//get all books published in 1950-2000, that is available in Hindi
MATCH (b:Book)
WHERE b.year IN RANGE (1950, 2000)
AND ANY (lang IN b.languages WHERE lang = 'Hindi')
RETURN b
Below queries are slightly more complex, uses relationships & pattern matching. For this part we’ll be using the sample Movies database available on neo4j site, that revolves around movies and people who are involved in them. This sample database also comes with the default installation of neo4j. Follow the instructions from the initial screen in the web interface to get the data. Jump into code -> Write code -> Movie Graph -> Create a graph. Or simply type “:play movie-graph” in the web editor.
//get uppercase names of all person that acted in movies, sort, skip first 10 and show 5 (pagination)
MATCH (p:Person) -[:ACTED_IN]- (Movie)
RETURN toUpper(p.name) AS Actor
ORDER BY p.name
SKIP 10 LIMIT 5
//get all movies and the crew (actors, directors, producers)
MATCH (p:Person) -[:ACTED_IN|:DIRECTED|:PRODUCED]-> (m:Movie)
Return m.title AS Movie, collect(p.name) AS Crew
//Return all person names, movie titles that acted in same movies with Tom Hanks
MATCH (Person{name:'Tom Hanks'})-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(p:Person)
RETURN p.name, m.title
//Return co-actors, no. of actors acted in same movies with Tom Cruise, grouped (implicit) by movie
MATCH
(Person{name:'Tom Cruise'})-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(p:Person)
RETURN m.title AS Movie, collect(p.name) AS CoActors, count(p) + 1 AS TotalCast
//UNION - get directors of all movies by Charlize Theron/Demi Moore. Union All to include duplicates
MATCH (:Person {name:'Charlize Theron'}) -[:ACTED_IN]-> (m:Movie) <-[:DIRECTED]- (p:Person)
Return m.title AS Movie, p.name AS Director, 'Charlize Theron' AS Actress
UNION
MATCH (:Person {name:'Demi Moore'}) -[:ACTED_IN]-> (m:Movie) <-[:DIRECTED]- (p:Person)
Return m.title AS Movie, p.name AS Director, 'Demi Moore' AS Actress
//Get all nodes that are directly related (in any direction) to Robin Williams
MATCH (Person{name:'Robin Williams'})-[]-(x) RETURN x
//find what role Tom Cruise played in movie Matrix
MATCH (:Person {name: 'Tom Cruise'}) -[r]-> (:Movie {title: 'The Matrix'})
RETURN type(r)
Query chaining
Sometimes there are more than one parts in a query and we want to pass or pipe the result from a MATCH to the next part of the query. Using the keyword WITH we can do that. Using WITH, we can process output from the previous part before passing on to the following part of query. It can be though to be a type of RETURN that passes data to next query part rather than the result set.
Look at the following query, we want to get all the movies that Charlize Theron acted in, ordered by movie title. We use collect() function to create a comma separated list. Since we could not use OREDR BY on movie title at the end (as it does not exist anymore after collect() as Movies), we pass along the movie variable and ORDER BY it before passing it to the RETURN.
MATCH (:Person {name: "Charlize Theron"}) -[:ACTED_IN]-> (movie)
WITH movie //movie being passed on to the next part
ORDER BY movie.title //process movie before RETURN
RETURN collect(movie.title) AS Movies
Variable length pattern matching
Variable length pattern matching is used when the level of relationship, or number of hops between the nodes can be variable. A variable length relationship is indicated with an asterisk (*) followed by a number pattern. In simplest form, (x)-[*2]->(y) denotes relationship between node x and y with exactly 2 relationships/hops in between, which is same as (x)->()->(y).
To have a variable length pattern, a range is used. For example, [*1..5] indicates relationship with 1-5 hops. [*3..] and [*..3] indicates minimum 3 and maximum 3 hops respectively. To indicate any/infinite number of hops [*] is used. Minimum hops by default is 1, but 0 can also be used to indicate no hops or the same node, e.g. in case of (a)-[*0..1]-(b), a and b can be the same node as well!
Let’s look at some examples in a typical social network, where people “know” other people, and direct relations are friends. Following queries can be used to find friends-of-a-friend and suggest new friends.
//get all friends of a person named Lily (which is a simple query)
MATCH (:Person {name: 'Lily'}) -[:KNOWS]-> (friend) RETURN friend
//get all second level friends of Lily (friend of a friend)
MATCH (p:Person {name: 'Lily'}) -[:KNOWS*2]-> (foaf)
WHERE NOT ((p) -[:KNOWS]-> (foaf))
RETURN foaf
//get all perople known to Lily upto 5 levels, not direct friends
MATCH (p:Person {name: 'Lily'}) -[:KNOWS*2..5]-> (foaf)
WHERE NOT ((p) -[:KNOWS]-> (foaf))
RETURN p, foaf
// ^ infinite level can be used [:KNOWS*], but query might be super expensive
//just a related query, find mutual friends between Maggie & Lucie
MATCH (:Person {name: 'Maggie'}) -[:KNOWS]- (mf:Person) -[:KNOWS]- (:Person {name: 'Lucie'})
RETURN count(mf) AS TotalMFs, collect(mf.name) AS MutualFriends
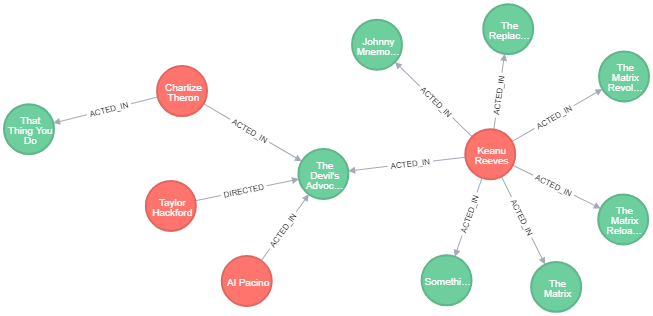
When finding relationships with multiple hops, neo4j avoids linking back to same node. So that it is not like (n1) -[:KNOWS]- (n2) -[:KNOWS]- (n1). Also, same nodes are also not included in result set, but can be added explicitly. Following is a sample query and the result set.
MATCH (p:Person{name:'Al Pacino'})-[*1..3]-(x) RETURN x, p
Data definition/schema
Neo4j does not have specific schema. But it allows some schema based constructs like Index and Constraints. They are conceptually the same as in other database systems. Index creates an ordered dictionary with specified property as key so that it’s easier for lookup. Unique constraints make sure there is no duplicate value for the given property within the same label.
Note: Unique constraint also creates an index implicitly. Unique key does not make the property to always have a value. For that existence constraint or node key can be used.
//create an index - does NOT make the property required/unique
CREATE INDEX ON :Book(name)
//DROP INDEX ON :Book(name) //to drop the index
//show all indexes & constraints across database
:schema
//using index hint, generally neo4j will figure out anyway
MATCH (b:Book)
USING INDEX b:Book(name)
WHERE b.name STARTS WITH 'Tintin'
RETURN b
//create unique constraint. Replace CREATE with DROP to drop
CREATE CONSTRAINT ON (b:Book)
ASSERT b.isbn IS UNIQUE
//show all constraints
CALL db.constraints
//following 2 features are available **ONLY ON Enterprise Edition**
//existence constraint - property must exist
CREATE CONSTRAINT ON (c:Character) ASSERT exists(c.Name)
//NODE KEY - must exist & be unique
//can also be combination of multiple properties (n.prop1, .prop2)
CREATE CONSTRAINT ON (n:Character)
ASSERT (n.name) IS NODE KEY
Deleting data
To delete an existing piece of data i.e. node or relationship, DELETE is used following a suitable MATCH pattern.
//DELETE ALL NODES, if there are no relationships
MATCH (n) DELETE n
//DELETE ALL NODES & RELATIONSHIPS, even if there are relationships
MATCH (n) DETACH DELETE n
//match and delete a node
MATCH (a:Author {name: 'Pran'}) DETACH DELETE a
//delete all characters, use DETACH to remove relationships too
MATCH (x:Character) DELETE x
//delete all characters without name
MATCH (c:Character)
WHERE NOT exists(c.name)
DELETE c
//delete all relationships of a node. DELETE c,r to delete node too
MATCH (c:Character {name: 'Tintin'}) -[r]- ()
DELETE r
//delete a whole path
MATCH path = (:Author) <-[]- (b:Book {isbn: 'aa002'})
DELETE path
DELETE is used to delete data, i.e. nodes & relationships. If you want to update data by removing properties or labels, use REMOVE as shown below.
Updating data
To set a value to a property, the SET command is used. If the said property already exists, it’s value is updated. Otherwise the property is added. To remove a property or label, REMOVE command is used.
//set properties to a node = add/update value
MATCH (m:Movie {title: 'Da Vinci Code'})
SET m.released = 2010, m.tagline = "The secret revealed"
//remove a property from a node (preferably, use REMOVE)
MATCH (b:Book{name: 'Da Vinci Code'})
SET b.printFormat = NULL
//add a label to a node
MATCH (n:Character {name: 'Billu'})
SET n:Fictional
RETURN n
//remove a property from a node
MATCH (a {name: "Tintin in Tibet"})
REMOVE a.isPdf
//remove a label from a node
MATCH (n {name: 'Tintin'})
REMOVE n:Fictional
RETURN n.name, labels(n)
Since NULL is not a allowed value for a property, setting null to a property removes it from the node. But it’s always better to use REMOVE to remove a property as it is more intuitive and makes it clear that the property is not removed by mistake.
Note: In the next article we’ll look at some practical routing problems in graph and how to solve them with Neo4j database.